导语
央视总台×阿里云联合发布《中国人工智能应用发展报告(2025)》,首次提出AI技术六大趋势正从实验室跃进千行百业。具身智能
多模态融合:打破感官边界,AI如何像人类一样感知世界?
1.技术逻辑:统一架构的跨模态理解
多模态融合的技术核心在于构建统一的语义空间,将文本、图像、音频等异构数据映射到同一向量空间中实现协同理解。其核心机制包含两个关键层面。

一是跨模态对齐,通过交叉注意力机制(Cross-Attention),模型能自动关联不同模态的语义信息。例如,文本中的“火警”一词可与图像中的火焰区域、音频中的警报声特征动态对齐,形成跨模态的语义关联。
二是特征级融合,先由独立编码器(如CNN提取图像特征、BERT提取文本特征)分别处理各模态数据,再通过加权拼接或注意力机制融合。这种分层处理既保留模态特性,又实现高阶语义整合。
对程序员而言,这一过程类似于游戏引擎处理多源输入:键盘指令、手柄震动和语音命令被统一转化为“玩家行为事件流”,最终驱动角色动作。

以GPT-4o为例,其突破性在于实时同步处理多模态输入:
音频频谱解析语调起伏,图像像素捕捉面部肌肉运动,文本语义分析对话内容;
Transformer层动态分配权重,例如根据声音的讽刺语调(如“真好”的声纹颤抖)和面部微表情(嘴角下撇),修正纯文本理解的语义偏差。
这种架构解决了传统单模态模型在跨场景交互中的语义盲区,为人机交互提供了更贴近人类认知的感知能力。
技术价值:解决传统单模态模型的“语义盲区”(如文字说“真好”,但语调讽刺)。
2. 案例实操:雷鸟AR眼镜的跨模态联动

技术实现路径:
1.输入层:
摄像头捕捉菜单图像→ 视觉模型(YOLOv7)定位菜品区域。
麦克风采集语音→ 语音识别(Whisper)转文本。
2.融合层:
使用Qwen2.5-Omni的多模态编码器,将菜品图像特征与语音转文本的特征向量拼接。
通过跨模态检索:匹配“海鲜饭”文本与图像中的虾类,触发过敏源检测模块。
3.输出层:
生成过敏警告语音 + AR界面高亮标注过敏成分。
3.产业价值:医疗诊断的融合革命
复旦伏羲模型的技术创新与行业影响

异构数据融合:
伏羲模型通过多模态数据处理架构整合气象与跨领域数据。针对气象时序数据(如温度/湿度),采用LSTM网络提取时间依赖特征;对于文本类数据(如病理报告或农业报告),则通过BERT模型解析语义信息。核心突破在于采用加权拼接的中期融合策略:将不同模态提取的特征向量动态融合后输入分类器,显著提升预测精度——相比单模态模型,跨领域预测任务准确率提升40%。
千倍加速的底层机制:
传统气象-病理关联分析需串行执行数据清洗、特征工程与模型推理,流程冗长且计算密集。伏羲模型创新性地引入图神经网络(GNN

行业变革性应用:
医疗健康:在哮喘发作预测场景中,模型实时融合气象台湿度数据与医院电子病历,预警响应速度从小时级压缩至秒级,为患者争取关键救治时间。
智慧农业:通过融合卫星遥感图像(识别作物病虫害特征)与土壤传感器数据(监测温湿度/酸碱度),构建虫害发生概率模型,预警准确率提升35%,指导精准农药喷洒与灌溉调度。

伏羲模型的异构融合架构重新定义了跨学科数据分析范式:
1.数据兼容性突破:支持气象时序数据、文本报告、遥感影像等异构输入,消除传统学科数据壁垒;
2.计算效率革命:GNN并行化处理使大规模气象-病理关联分析成本降低90%,赋能边缘设备部署;
3.长尾场景覆盖:在医疗资源匮乏地区,基于气象数据的哮喘预测可替代部分病理检测需求,缓解诊断资源不平等。
伏羲模型的成功印证了“气象+垂直领域”融合的技术红利——未来可通过复用其融合框架,快速适配金融(气候风险定价)、能源(风光发电预测)等场景,推动AI跨产业渗透。

程序员为什么需要关注多模态融合?
(1)开发范式变革:
传统:为每类数据单独开发处理流水线(如OpenCV处理图像 + Librosa处理音频)。
多模态:统一API调用(如transformers.pipeline(task="multimodal"))。
(2)硬件协同优化:
云边端分工:云端训练大模型→ 边缘端部署融合引擎 → 终端设备轻量化推理。
(3)新工具链崛起:
LangChain构建多模态Agent:10行代码实现“图片搜索+语义过滤”。

二、具身智能爆发:机器人从“提线木偶”进化为“物理世界超级员工”
1.技术逻辑:“大脑+小脑”架构如何实现自主交互?
(1). 核心架构拆解
大脑层(大模型规划层)作为系统的核心决策单元,承担高阶任务解析与规划功能,其角色类似软件架构中的业务逻辑层。该层通过Transformer模型
小脑层(运动控制层)则类似前端渲染引擎,负责将大脑生成的抽象指令转化为物理动作,并实时处理传感器数据以微调关节运动。其技术实现包含两大核心:
一是动态避障:融合激光雷达点云与视觉SLAM技术构建环境三维地图,采用RRT*等算法实时优化避障路径,确保移动过程中对突发障碍物的快速响应;
二是精细操作:通过六维力矩传感器实现触觉闭环控制,动态调整机械臂抓取力度(如捏鸡蛋不碎),解决传统机器人因力控缺失导致的物体损坏问题。
大脑与小脑的协同通过双向数据流实现闭环:
大脑输出动作序列指令至小脑,例如“抓取A货架第三层的玻璃杯”;
小脑将力觉传感器数据、关节位姿偏移等物理状态实时回传大脑,触发动态调整(如检测抓取力度不足时增强扭矩)。
这种架构使机器人从“被动执行”进化为“主动适应”,在仓储物流、康养陪护等场景中实现类人的环境交互能力。

(2). 交互闭环的关键:感知-决策-执行一体化
传统机器人系统采用感知、规划、控制模块分立架构,各环节通过标准化接口传递数据。这种模块化设计虽便于分工开发,却导致数据在传递过程中产生累积延迟。例如当机器人遇到突发障碍时,感知模块需先识别障碍物位置,规划模块重新计算路径,再交由控制模块调整运动指令。多环节串联处理使得动态场景响应滞后,无法满足毫秒级实时交互需求。
具身智能系统则通过硬件与算法的协同重构解决了这一瓶颈:
硬件层面,视觉传感器、力觉反馈单元、关节位姿编码器等多模态传感器数据直连控制芯片(如NVIDIA Jetson AGX Orin),原始数据通过高速总线(如PCIe 4.0)直接传输至边缘计算单元,实现感知到执行的端到端延迟压缩至<50ms。
算法层面,采用端到端模型(如Google SayCan),将自然语言指令(如“绕过障碍物”)直接映射为动作编码,并生成关节角度控制序列。该模型通过跨模态对齐技术跳过传统架构中的中间编码层(如目标检测框→路径坐标→速度指令的多步转换),显著提升动态环境适应性。

2. 案例实操:从代码到物理世界的工程实现
案例1:阿里云通义灵码
以下是阿里云通义灵码在仓储调度场景中的技术实现路径与价值说明,采用自然段形式组织:
技术实现路径:
当用户输入自然语言指令(如“每小时巡检A货架并补货”)后,通义灵码的大模型层首先解析指令语义,将其拆解为原子任务链:

路径规划:基于A货架位置生成最优移动路线;
视觉识别:通过摄像头捕捉货架图像,定位缺货商品并计算补货数量;
机械臂抓取:根据识别结果控制机械臂执行精准抓取和放置动作。
在执行过程中,系统通过激光雷达实时构建2D栅格地图,结合AI算法动态优化路径。例如当检测到移动叉车等突发障碍物时,自动重新规划绕行路线,确保任务不间断推进。同时,基于强化学习的多机器人协同调度引擎优化任务分配策略,使10台机器人的协作冲突率降低80%,避免资源闲置或重复作业。
该方案显著压缩了仓储系统的部署周期——传统定制化编程需3个月完成的任务,通过通义灵码的自然语言驱动架构缩短至1周。其核心价值在于:
仓储效率提升40%:机器人动态避障与智能调度减少了空转等待时间;
零代码部署:无需针对每类任务编写专用脚本,通过自然语言指令即可适配新需求;
弹性扩展能力:强化学习模型持续优化多机器人协作效率,随业务规模扩容无需重新开发。
这一案例印证了自然语言编程在工业场景的落地可行性——开发者只需描述业务目标,底层路径规划、感知决策等复杂逻辑均由AI自动生成并执行,大幅降低自动化系统的开发与维护门槛。

案例2:天工2.0机器人
技术突破点:
仿生运动算法:模拟人类小脑的“预测-校正”机制(如踩碎石时预判足底打滑,提前调整重心);
抗干扰控制:
斜坡稳定性:基于IMU(惯性测量单元)数据实时计算倾角,调整关节扭矩分配;
精细操作:倒闸操作误差≤0.1mm(依赖高精度编码器+力控伺服电机)。
工程挑战:户外光照变化导致视觉识别失效 → 解决方案:融合红外热成像+3D点云冗余感知。

3.产业落地:从实验室到千亿市场的爆发逻辑
(1). 规模化落地数据
2025年部署1.5万台人形机器人:主要覆盖三大场景:
工业场景(50%):工厂巡检、高危设备操作(如电网倒闸);
康养陪护(30%):情感交互+基础护理(如傅利叶GR-1端茶递水、抱老人起床);
家庭服务(20%):清洁、安防(如暴雨中巡逻的机器狗)。

(2). 康养机器人的技术实现
情感反馈机制:
A.多模态感知:麦克风阵列捕捉语音情绪(如声纹颤抖→焦虑),摄像头识别面部表情;
B.情感计算:CNN+LSTM模型分析情绪类型,生成响应策略(如播放舒缓音乐);
C.安全执行:力控机械臂实现轻柔动作(抱人力度<5N,类似人类手臂)。
D.成本优化:采用“云脑+端侧小脑”架构,本地仅部署轻量化模型(3亿参数),降低硬件成本30%。

三、云边端协同:中小企业的“轻量化AI革命”破局点
1.技术逻辑:像“分布式系统”一样分配AI任务
核心架构:

云端训练:相当于在“数据中心”用GPU集群训练大型神经网络(如百亿参数的GPT-4),耗时数天但只需周期性更新。
边缘推理:在靠近终端的边缘服务器(如工厂机房部署的NVIDIA Jetson AGX Orin)运行蒸馏压缩后的模型,响应延迟<50ms。
端侧执行:终端设备(耳机/传感器)直接处理实时数据,避免网络传输开销,功耗降低60%。

2.降本案例:智能耳机的“端侧AI优化术”
(1)技术实现路径
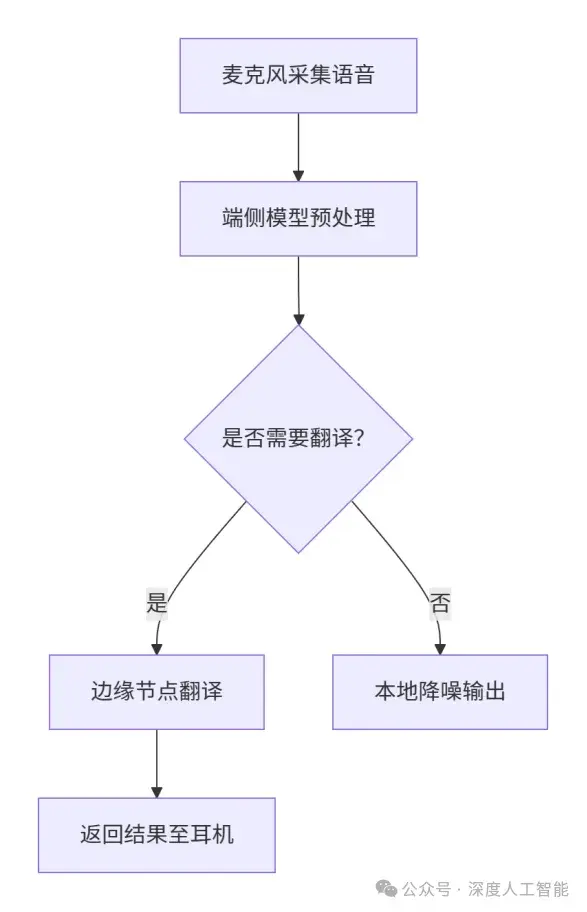
智能耳机的端侧AI优化核心在于模型压缩与功耗控制的双重革新。原始大模型如GPT-3(1750亿参数)因体积庞大无法在终端设备运行,通过知识蒸馏技术将大模型的知识迁移至轻量化模型TinyBERT(3亿参数),使模型体积缩小98%。进一步采用量化技术(FP32浮点数→INT8整数),在保证精度损失<2%的前提下,显著降低计算复杂度。
压缩后的模型可直接部署于耳机嵌入式芯片,实现端侧实时推理,耗电量仅0.2W——相当于一颗LED指示灯的功耗。对比云端方案(调用云端模型耗电0.5W + 网络传输额外功耗),端侧方案综合功耗降低60%,彻底解决实时降噪、语音翻译等场景的续航瓶颈。

(2)工程挑战与解决
实时性:端到端延迟<200ms(人耳无感知)
→ 方案:端侧预过滤无效语音,仅关键语句触发边缘翻译
内存限制:耳机内存仅4MB → 方案:模型剪枝移除冗余层(如减少Transformer头数)
3.工具链推荐:LangChain构建“行业热点雷达”
(1) 10分钟快速搭建流程
Python
# 伪代码示例:Dify + LangChain构建Agent
from langchain.agents import create_csv_agent
from dify_client import DifyAPI
# Step1:爬虫抓取展会数据(本地运行)
spider.run("WAIC参展商名单.csv")
# Step2:本地小模型过滤噪声(边缘节点)
agent = create_csv_agent('gpt-3.5-turbo', 'WAIC参展商名单.csv')
clean_data = agent.run("过滤非AI硬件企业,保留新品发布信息")
# Step3:云端大模型生成报告
dify = DifyAPI(api_key="xxx")
report = dify.generate_report(clean_data, prompt="分析2025年AI芯片趋势")
(2). 关键技术解析
LangChain核心价值:
封装AI任务链(Chains) → 像写Shell脚本一样串联AI模块
支持本地/云模型混用(如本地过滤用ChatGLM-6B,云端分析用GPT-4)
边缘-云分工:
边缘:运行轻量模型(ChatGLM-6B)过滤80%无效数据,降低云端成本
云端:仅处理高价值数据,生成报告成本从0.1/次降至0.02/次
4.中小企业落地路径:从“玩具项目”到“生产级应用”
(1). 成本对比(传统 vs 云边端)
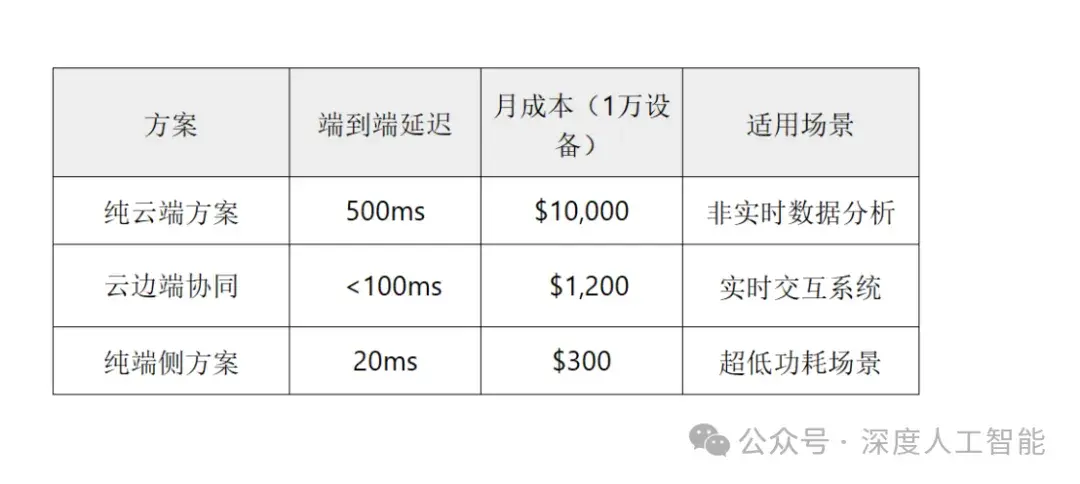
数据来源:某智能耳机厂商实测报告
(2). 开源工具链推荐
模型压缩:TensorFlow Lite(量化工具)、Distiller(知识蒸馏框架)
边缘部署:NVIDIA Triton(边缘推理服务器)、Apache TVM(模型跨平台编译)
任务编排:LangChain(AI工作流)、Prefect(调度监控)

5.为什么这是中小企业的“破局点”?
(1)成本杀手锏
通过“云端训练一次,边缘部署多次”的架构设计,中小企业可将大模型研发成本(如训练算力、算法优化)分摊至数千台终端设备,显著降低单设备边际成本。同时,端侧推理功耗比云端方案降低60%(如耳机端耗电仅0.2W),直接提升智能硬件续航2小时以上,直击用户续航焦虑痛点。
(2)技术民主化
借助LangChain + Dify等低代码开发平台,企业可通过“拖拉拽”方式快速搭建AI应用链(如“爬虫→本地模型→云端GPT”工作流),无需专业机器学习团队支持。例如,复现“热点雷达”案例时,仅需串联本地爬虫(数据采集)、端侧模型(实时分析)和云端大模型(深度推理),大幅降低开发门槛和人力成本。
(3)合规优势
端侧AI将敏感数据(如会议录音、健康信息)在本地设备完成处理,避免原始数据上传云端,天然符合GDPR等隐私法规要求。以讯飞会议耳机为例,其录音转写与摘要生成功能完全在设备端运行,既保障企业数据安全,又规避跨境数据传输的法律风险。
程序员端侧AI行动指南
A. 端侧推理入门:使用TensorFlow Lite压缩MNIST手写数字分类模型,在Android/iOS设备实现端侧部署,掌握模型量化(FP32→INT8)与内存优化技巧。
B. 混合架构实战:通过LangChain串联本地爬虫(抓取新闻)、端侧轻量化模型(关键词提取)、云端GPT(热点分析),构建“热点雷达”系统,体验云边协同推理。
C. 边缘节点部署:在树莓派上部署边缘计算节点,结合OTA(空中下载)技术实现模型热更新,验证分发热修复机制对长尾设备的兼容性。

四、AI基础设施:万亿美元市场的隐形地基与中小企业借力路径
1.技术逻辑:AI基础设施的“分层架构”与核心突破
分层架构类比
将AI基础设施类比为操作系统内核:
算力层(硬件) → 相当于CPU/GPU,负责底层计算(如华为昇腾集群
数据层(资源) → 相当于内存/硬盘,存储和调度数据(如合成数据集);
工具链(API) → 相当于系统调用接口(如通义灵码API)。

技术突破点:
算力国产化:华为昇腾集群通过软硬协同优化(如达芬奇架构+昇思MindSpore框架),实现训练效率提升40%、能耗降25%。
程序员类比:就像用Rust重写Python计算库,通过内存安全性和并行优化提升性能。
数据新范式:合成数据技术
技术价值:相当于用Unity引擎生成虚拟测试环境,替代物理世界高成本试错。
2.核心支撑:算力与数据的“性能优化术”
(1)算力国产化:从“卡脖子”到“超车引擎”
华为昇腾的三大技术突破:
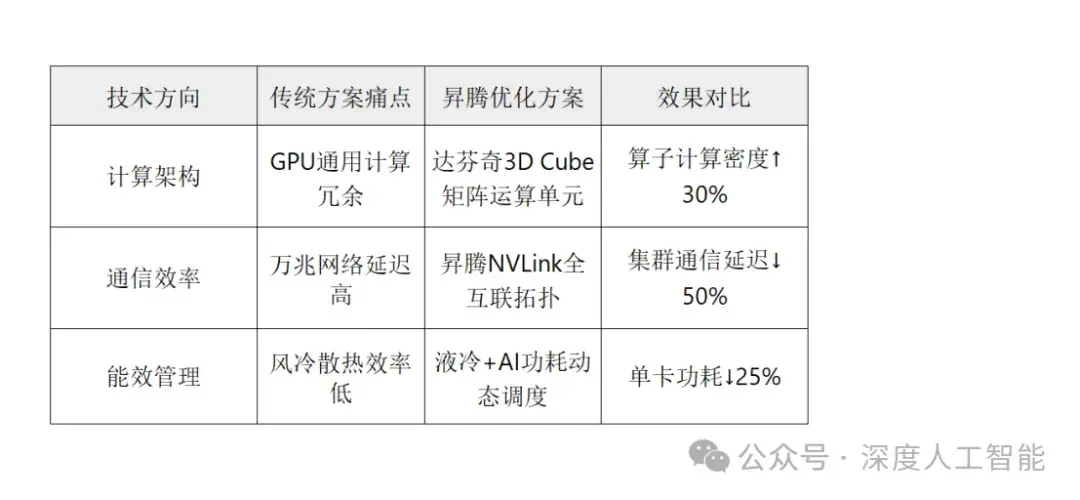
产业影响:
金融风控模型训练从3天→1.8天,中小银行推理成本降低60%;
国产AI芯片(如海光DCU)规模化落地,大模型推理成本降至$0.001/次。
(2) 数据新范式:合成数据的“造物主模式”
工业质检的技术实现路径:

关键技术:
可控生成:调整GAN的潜空间向量,精确控制缺陷形态(如裂纹长度/方向);
域适应:添加风格迁移模块,让合成数据匹配不同工厂的光照环境。
降本价值:
传统方案:采集10万张瑕疵图需6个月,成本$50万;
合成数据:同等规模数据集生成仅1周,成本$5万。

3.中小企业借力路径:“不造轮子”的生存策略
(1)普惠智算池:算力领域的“共享充电宝”
政府主导的算力租赁模式:
北京AI产业园案例:
提供100P(1P=1000张A100算力)国产算力池;
支持按小时租赁(¥8/卡时,比公有云低35%);
集成预训练模型库(OCR/语音识别等开箱即用)。

操作流程:
申请政府“算力券”(补贴30%费用);
通过Web界面选择模型框架(PyTorch/MindSpore);
上传数据→启动训练→下载模型。
(2)AI API优先策略:避免“重复造轮子”
通义灵码的工程实践:
Python
# 传统方案:自建NLP模型需200行代码
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
model = AutoModel.from_pretrained("bert-base-chinese")
# ...(还需部署/优化/维护)
# API方案:10行代码调用通义灵码
import dashscope
dashscope.api_key = 'YOUR_API_KEY'
response = dashscope.Generation.call(
model='qwen-plus',
prompt='分析用户评论情感:这款耳机音质太差了'
)
print(response['output']['text']) # 输出:负面评价
成本对比:
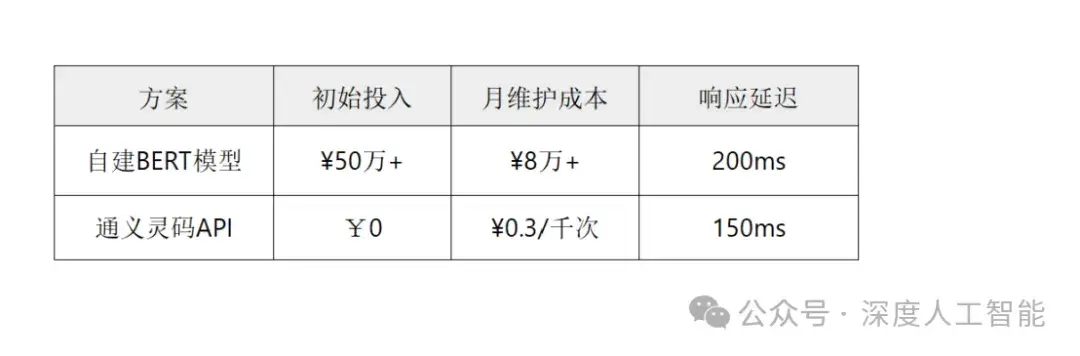
适用场景:
客服机器人(会话理解)、供应链预测(时序分析)、营销文案生成(AIGC)。

结语:
总结:多模态大模型通过技术统一化、行动自主化、设施普惠化,正推动产业从“效率优化”迈向“范式重构”。其本质是以“感知-决策-执行”闭环重塑生产力体系,最终实现 “智能定义业务,数据驱动价值”的新经济逻辑。

官方服务号,专业的人工智能工程师考证平台,包括工信部教考中心的人工智能算法工程师,人社部的人工智能训练师,中国人工智能学会的计算机视觉工程师、自然语言处理工程师的课程培训,以及证书报名和考试服务。













